参考
CycleGAN论文:https://ieeexplore.ieee.org/document/8237506
本文是在经典的无监督风格迁移模型cycleGAN的基础上进行探究,提出了一种改进的,针对人类头像动漫化风格转换的新模型。
虽然改进的点不多,改进的创意也不是很新,效果提升也没有很大,但是,这是我深度学习和科研的入门项目!
通过这个项目,我大概了解了深度学习中如何构建网络模型、设置损失函数、调整数据集的输入输出、如何训练好一个模型,再调用已训练的模型进行风格迁移,以及在训练过程中定期保存模型参数checkpoint等。
下面我将梳理这个项目的模型结构。
模型结构
作为生成对抗网络(GAN)领域的无监督算法,在本算法中,我们设置了两个生成器和两个判别器,其中,生成器Generator(A2B)和判别器Discriminator(B)用于生成和分辨目标域风格图像;生成器Generator(B2A)和判别器Discriminator(A)用于循环生成和分辨源域风格图像。在训练过程中,会单独训练生成器和判别器。
图片中展示了模型的整个网络结构的关系。
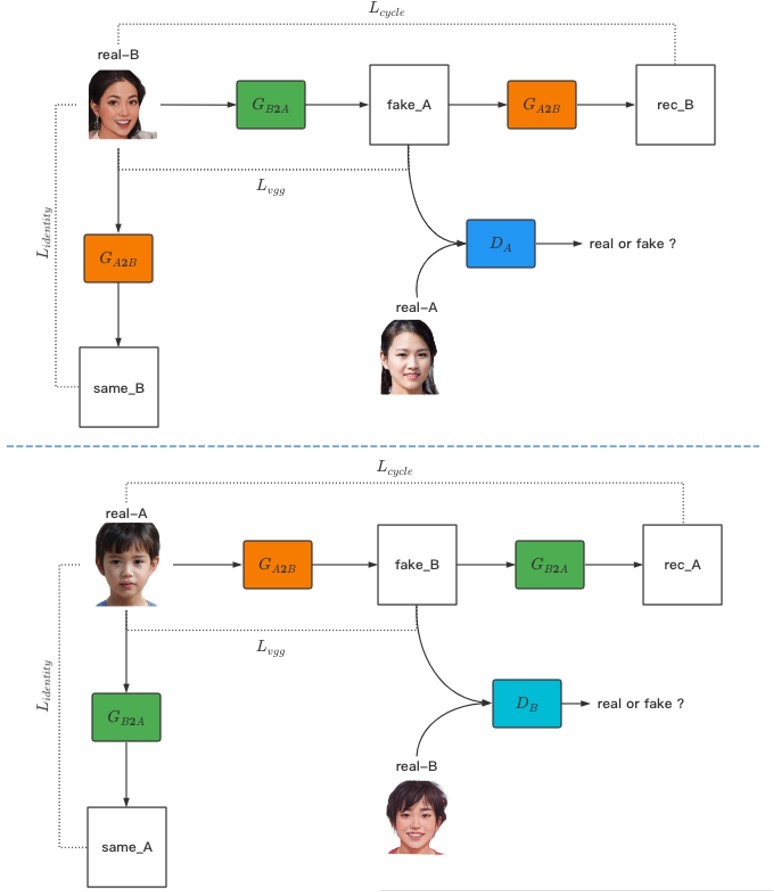
图中,两个生成器为 G_A2B 和 G_B2A ,两个判别器为 D_A 和 D_B ,另外包括源域图像real_A、目标域图像real_B、生成的目标域图像fake_B和生成的源域图像fake_A、由fake_B循环生成的源域图像rec_A和由fake_A循环生成的目标域图像rec_B,以及输入real_A图像至生成器 G_B2A 得到的same_A、输入real_B图像至生成器 G_A2B 得到的same_B。
残差网络
本文算法在生成器网络中加入残差模块,残差模块的结构如下图所示。

生成器
本文算法的最终任务是一幅真实人像风格的图片经过模型可以转换得到动漫风格的人像图片。同时,因为本文算法模型使用循环生成网络结构,所以设置两个结构相同,作用不同的生成器,它们分别是用于生成动漫风格图像的Generator(A2B)和生成真实人像风格图片的Generator(B2A)。
该生成器由下采样、上采样模块和转换模块组成,为了使生成器的训练更稳健,还加入了残差模块,考虑到本实验中经过数据预处理后得到的输入图像大小为 像素,因此选择加入的残差模块数量为9个,残差模块的结构细节见3.1.1节。在生成器网络中,使用IN(Instance Normalization)对图像做归一化操作,使用ReLu作激活函数。生成器网络的结构如下图所示

判别器
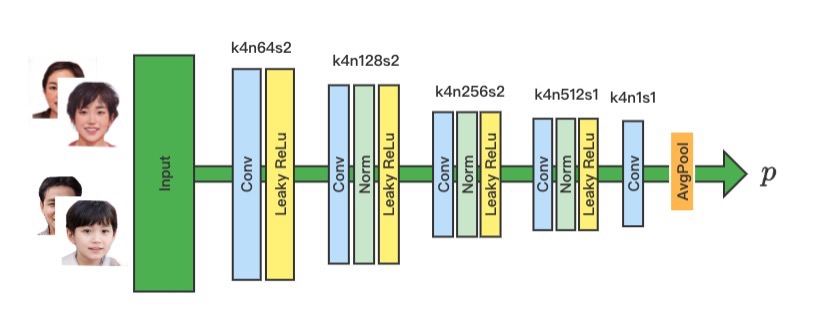
在本文算法模型中,判别器的功能是分辨输入的图像为真实的图像或为生成器生成的,由于是循环生成网络结构,我们同样设置两个结构相同,作用不同的判别器,用于判断不同风格域图像的真实性。在判别器网络中,使用IN(Instance Normalization)对图像做归一化操作,使用LeakyReLu作激活函数。网络结构如下图所示:
损失函数
损失函数(Loss Function)是用来衡量模型的预测值与真实值之间的差异,是一个非负实值函数,一般使用来表示,损失函数可以保证模型朝着理想的方向进行优化,好的损失函数能够使模型的训练过程更加稳定,得到的模型的性能更好。模型的预测值与真实值之间的差异程度称为损失值,但通常而言,损失值并不是取得极小时最佳,这样会导致模型出现过拟合的情况。损失函数参与模型训练的具体流程如下:首先,给模型中的各参数赋随机值,然后将训练样本输入到模型得到输出值,利用损失函数计算该输出值与目标值之间的损失,根据该损失值反向传播去更新模型中计算公式的参数值。重复以上步骤,逐渐降低损失函数的结果值,最终使输出朝着期望的方向靠拢,以达到学习的目的。
感知损失
添加这个损失函数是我的一个创新点。
将源域图像转换到目标域图像的生成器Generator(A2B)在生成动漫头像时,不仅要保证所生成的图像具有动漫风格,还需要该图像同时保持原图片中人物的形象特征,比如生成的图像要能在除面部纹理、阴影高光和头发丝等细节方面同原图像尽量保持一致,这样使每幅动漫人像面孔都有各自的特点,达到“千人千面”的效果。
假使本算法中的真实人像图片为real_A,生成器Generator(A2B)生成的动漫图像为fake_B,在本模型的结构中,我们在real_A和fake_B之间、real_B和fake_A之间加入了感知损失,该损失函数如式(1)所示:
式中,h(·)是对图像进行特征提取得到的特征值,本算法利用预训练好的卷积神经网络VGG-16的特定特征层进行图像特征提取,分别提取到两幅图像的特征值后,再对其做平均绝对误差(Mean Absolute Error,MAE)计算,即通过降低生成图像和原图像之间的高维特征的差异,使得生成的fake_B在一个特定的特征空间能够最大限度与real_A相同。
VGG-16网络共有13个卷积层,5个池化层和3个全连接层。2015年,Gatys等学者在其风格迁移的论文工作中提到,卷积网络的深度能够直接影响到对原图像特征信息的提取力度,其中,较浅的卷积层提取得到的特征,能够很好地保持着原图像的像素值;较深的卷积层提取得到的特征有利于保留原始图像的整体结构等更高层次的信息,但是越深的卷积层提取得到的特征,会更难重构出准确的像素值。因此,对于VGG-16网络特征层的选择是相当重要的,本小节加载官方预训练好的VGG-16神经网络模型,对网络每一层提取得的特征图进行可视化展示,展示结果如图 3.6所示,该图一共展示了VGG-16网络的其中五个卷积层的结果,从左至右分别是conv1-2、conv2-2、conv3-3、conv4-3和conv5-3。可以看到,conv2-2层通过高度锐化的形式将原图像中人脸的轮廓信息、高光阴影等诸多细节展现出来,相反,VGG-16卷积网络的最后一个卷积层conv5-3层的画面是非常抽象的,原图像中的人脸五官,甚至面部轮廓信息都已不复存在。

生成对抗损失
本文算法是基于生成对抗网络(GANs)的图像风格迁移算法,核心思想是生成器与判别器相互对抗:生成器力求输出能够混淆判别器判断的图像,判别器力求准确地分辨真实图像和生成图像,它们各自朝着最优的方向进行优化,最终达到一个平衡状态。为了使模型训练更加稳定,对于生成对抗损失的表达,本文算法选择使用最小二乘损失(Least-Squares Loss)而不是传统GAN模型中的负对数似然函数。
训练生成器Generator(A2B)时,通过本小节的生成对抗损失使其朝着理想的方向不断优化:输出与目标域风格高度相似的动漫图像,导致目标域风格的判别器Discriminator(B)将此生成图像判断为真实的目标域图像,即;对于生成器Generator(B2A),则希望等式成立。因此,在固定住判别器时,单独训练两个生成器的生成对抗损失函数如式(2)所示:
循环一致性损失
作为无监督的用于图像到图像转换的算法,本模型使用了A→B→A和B→A→B的循环生成结构,以及用于约束生成器的循环一致性损失函数。该损失函数能够保证生成器Generator(A2B)所生成的动漫风格图像在尽可能骗过判别器Discriminator(B)的情况下,依然能通过生成器Generator(B2A)还原到初始样貌,这样能避免生成器陷入一个错误的学习方向:不论原始图像是什么样,生成的图像只需与目标域图像风格相似即可。
与上一小节中图像的命名类似,本小节中依然称原始图像为real_A,生成器Generator(A2B)生成的图像为fake_B,fake_B再次经过Generator(B2A)生成图像recovered_A。本文算法的模型结构便是选择在real_A和recovered_A之间、real_B和recovered_B之间设置循环一致性损失,该损失函数是对两幅图逐像素做平均绝对误差计算,以此使得real_A和recovered_A、real_B和recovered_B尽可能保持相同。损失函数如式(3)所示:
身份损失
在本文算法中,生成器Generator(A2B)是用于生成动漫风格图像,那么,当我们选择输入一张本就是该动漫风格的图像real_B时,该生成器应该要仍然生成“real_B”,即生成的动漫图像(按照上面的规范称为fake_B)与原始图像real_B的数据分布尽可能靠近,只有这样我们才能证明生成器Generator(A2B)具有生成动漫风格图像的能力。同样,对于生成器Generator(B2A),也需要加入一个身份损失来保证其具有从动漫风格图像转换到写实风格图像的能力。在实验中我们还发现该身份损失能够让图像在风格迁移过程中保持原色调。
综上所述,我们在real_B和fake_B之间、real_A和fake_A之间加入身份损失,该损失函数同样是对两幅图逐像素做平均绝对误差计算,迫使两幅图像尽量保持相同。损失函数如式(4)所示:
总的损失函数
- 训练生成器
Generator(A2B)和生成器Generator(B2A)时:
- 训练判别器
Discriminator(A)时:
- 训练判别器
Discriminator(B)时:
至此就完成了模型主体结构的理论部分,我将在下一篇文章中发布PyTorch版本的代码部分!
附上我的模型效果图!




